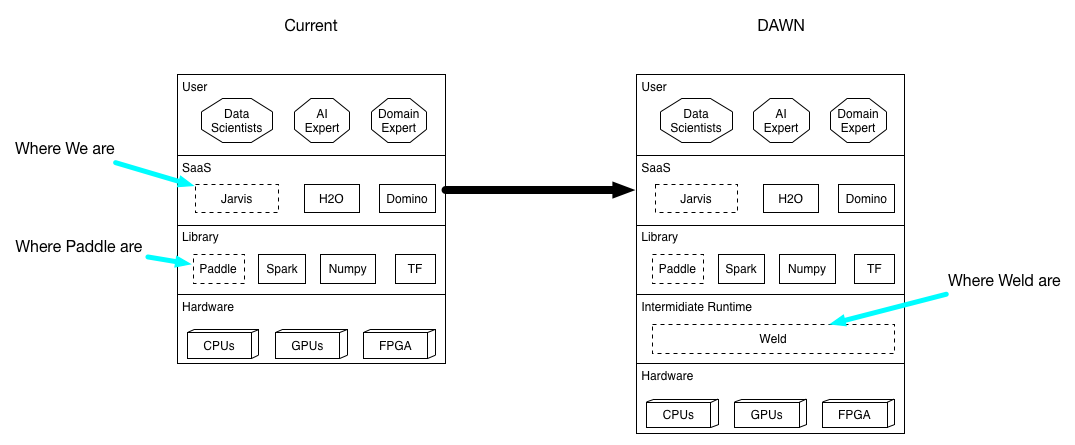
下一代数据分析系统-Weld项目-调研
核心是通过增加虚拟中间层Weld, 统一加速了数据密集型应用跨库访问的数据并发性能优化问题;
Weld 调研
思考
简介
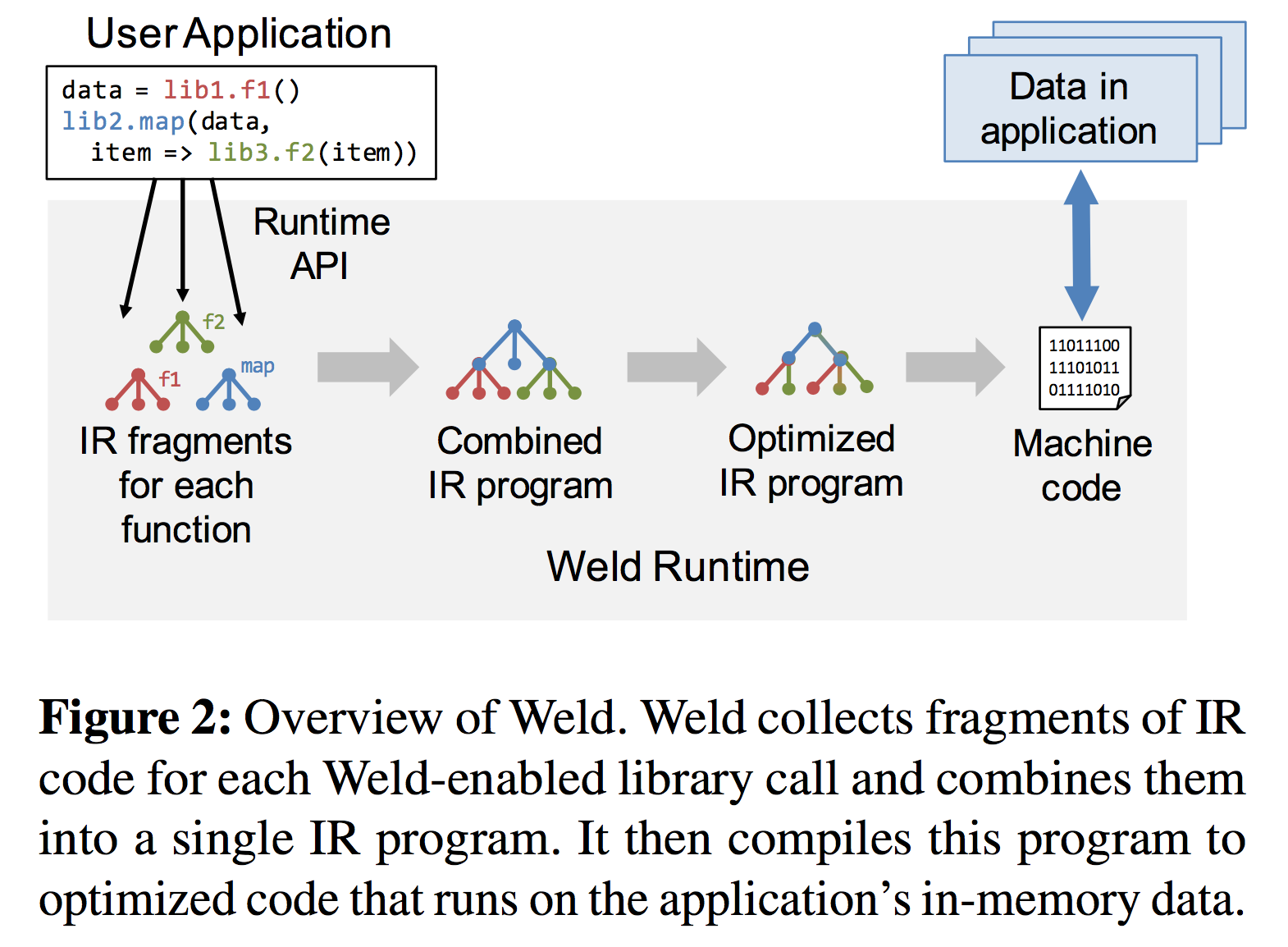
数据分析应用会把很多函数、库、框架组合起来。 尽管每个函数、库、框架各自都进行了独立的优化,但是应用整体的性能还是远低于硬件瓶颈。这个原因主要是因为框架之间的数据来回移动占据了太多的时间。为了解决这个问题,我们提出了 weld,一个处在数据密集型的库、框架之间并且能够提升这些独立的库、框架性能的新型接口。weld 对外暴露了一种懒汉式的API,各种各样的函数都能通过这个API将自己的计算过程转变成一种简单的但是通用的中间表示,这个中间表示刻画了数据并行的结构。接下来这个API对这些函数之间的数据转移进行了优化,并且为各种不同的硬件设施都提供了高效的代码。weld可以在不改变框架用户侧代码的情况下集成到框架中,比如Spark,Numpy,Pandas, Tensorflow等。我们证明了weld可以将使用这些框架的应用整体提速29倍。
整体设计
2.1 主要设计目标:
- Runtime API & Weld IR: 对于数据密集型的工作流, 利用基于 Loops (一种能够按DAG并行执行Loop的机制) 和 Builders (一种和硬件无关的, 对计算的抽象定义) 的通用IR, 和懒汉式的Runtime API (代码执行时将IR提交到API执行), 实现跨库跨方法的整体优化;
- Weld Optimizer: 针对不同的CPU和硬件, 对IR的执行进行优化;
- Weld 最后的效果评估, 整体提升一个集成了 Numpy, Pandas, Tensorflow, Spark 的工作流的速度 (29倍);
整体视图
3.1 集成Weld的两种方式:
- Numpy式: Numpy已经有自己的内存数据设计, 有自己的关键算法设计, 对于这种的库, 直接把函数迁移到Weld即可, 因为数据就在内存中, 所以Weld没有额外开销, 直接就能提升整体流程;
- Spark SQL式: 包含 SQL -> Code 的 Generator 和 Code 的Runtime, Weld提供两种形式:
更高效的Generator(大部分Generator就是把一个算子的DAG转变成一个对于数据的Loop, 而Weld可以提供更简单的Loop Fusion 什么是Loop Fusion, 保证高效);
在Runtime时和Numpy这样的库更高效的结合;
(还有一些领域相关的优化, 比如 线代表达式重排, JOIN的重排 等等, 仍然需要在Weld之外去做, 所以Weld除了IR库还提供了C库去做这些事情)
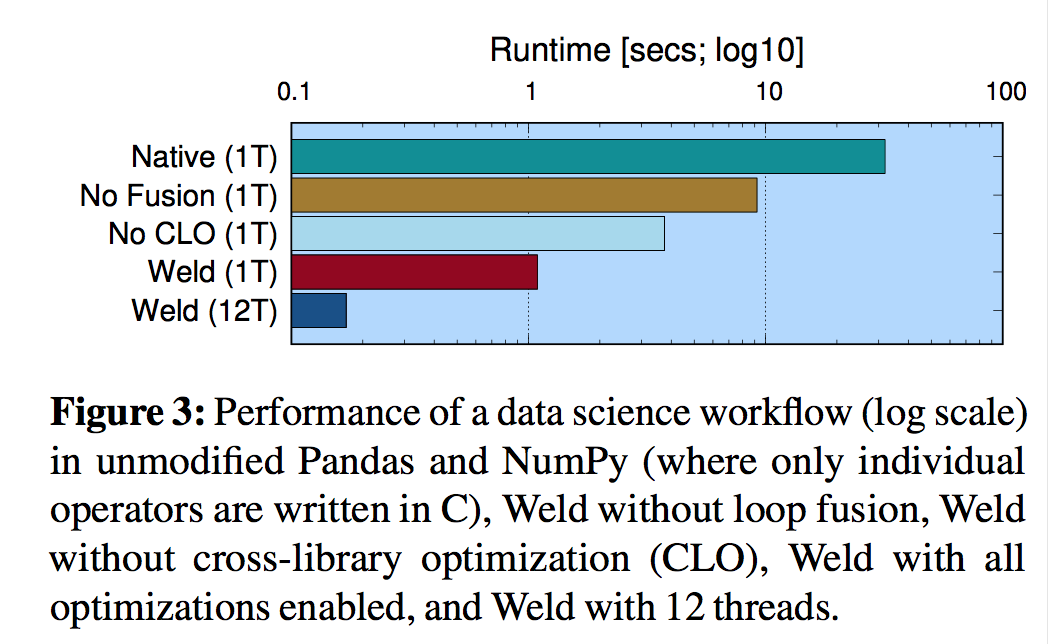
3.2 集成Weld的效果:
Weld -> 3倍 -> Weld Fusion -> 2.8倍 -> Weld Cross Library Optimization -> 3.5倍 -> 12线程 -> 6.3 倍, 整体187倍
3.3 集成Weld的限制:
- Weld只支持单机优化 (多核, 共享内存), IR会使用一些对向量的随机查询, 这个在分布式环境很难实现, 但是分布式各个单机节点的优化还是可以用Weld做的 (Spark 5-10倍); 不支持实现本地化 (CPU cache相关的操作);
- Weld 不支持异步计算; (不能处理线程的竞争关系)
- Weld 不支持debug; (只能Log)
- Weld 必须修改库实现; (所以提供了C接口和IR接口)
4 IR的实现
4.1 设计目标
- 通用: 支持所有数据处理操作 (关系型和线性代数类);
- 支持Loop Tiliing之类的编译优化;
- 显示并发, 利用多核; 设计灵感来自于 Monad comprehension
4.2 支持的数据类型
- scalars: int and float;
- 变长数组;
- 结构; (就是类)
- 字典; 这些数据类型是大部分数据密集型应用会使用的数据类型;
4.3 具体实现


Weld底层只支持 merge(支持并发), for(支持并发), result 三种算子, 基于这三种算子实现了 map reduce filter 这些高级算子;
Builders 可以理解为 数据结构, Loop 和 merge 算子可以理解为对于这些数据结构的操作;
-
Optimizable: 基于 Loop & Merge 去做 (可以做 Loop Fusion Tiling 等);
-
General: Loop & Merge + Builders 可以表达所有的数据操作 (实在表达不了, 就不做呗);
-
Parallel: merge 和 for 都支持并发 (分CPU去做for循环);
4.4 优化示例
data := [1,2,3];
r1 := map(data, x => x+1);
r2 := reduce(data, 0, (x, y) => x+y)
data := [1,2,3];
result( for(data, { vecbuilder[int], merger[+,0] },
(bs, i, x) => { merge(bs.0, x+1), merge(bs.1, x) }
)) // returns {[2,3,4], 6}
5 Runtime API的实现
5.1 联合优化
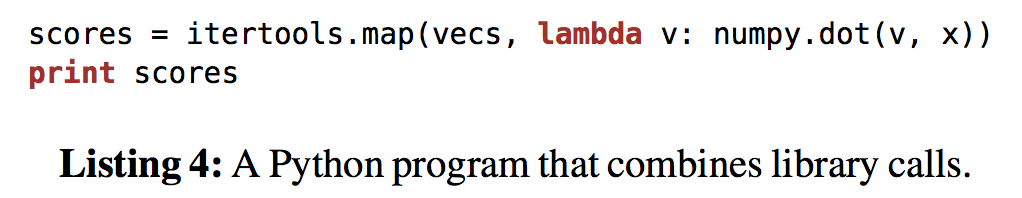
对于map来说, 每次vecs都要被装入CPU L1-L3 级别的 Cache, 通过Weld的话, 只用装入一次就好;
5.2 内存管理
Weld将数据分为两块, Library数据和Weld数据:
- Library数据由Library管理, 和Weld无关;
- Weld数据由Library传入的数据产生, 并由Weld管理;
- 可以通过Runtime API指定Weld的内存池的大小;
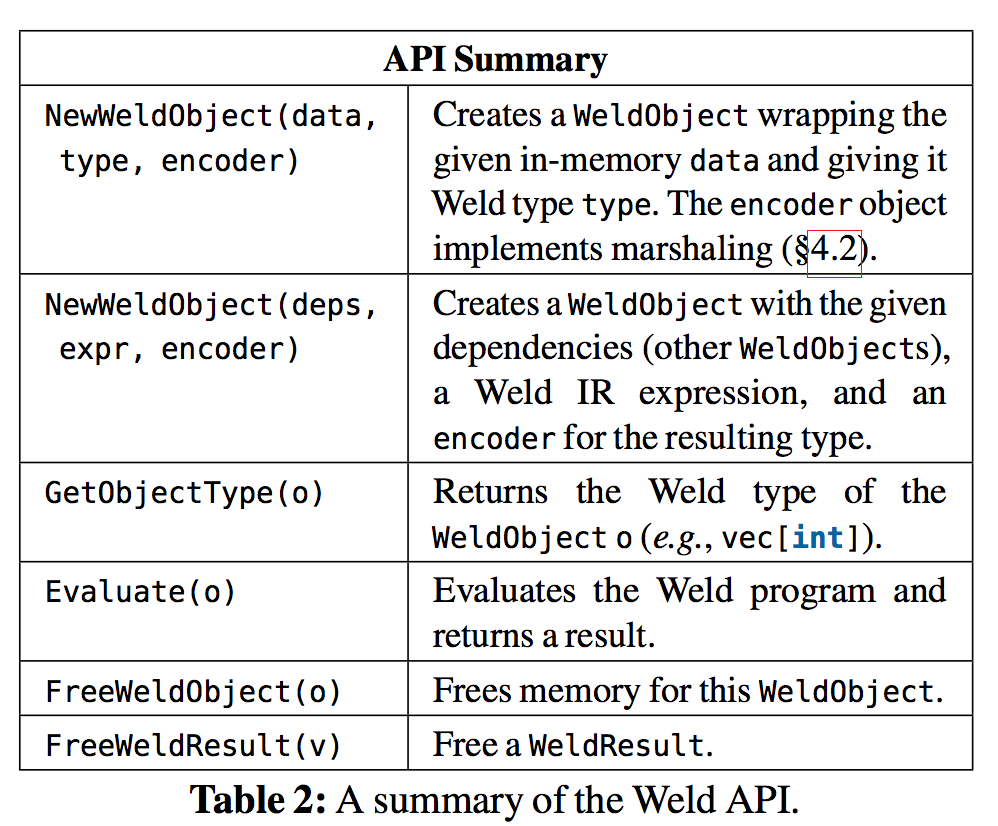
5.3 Runtime API 具体内容
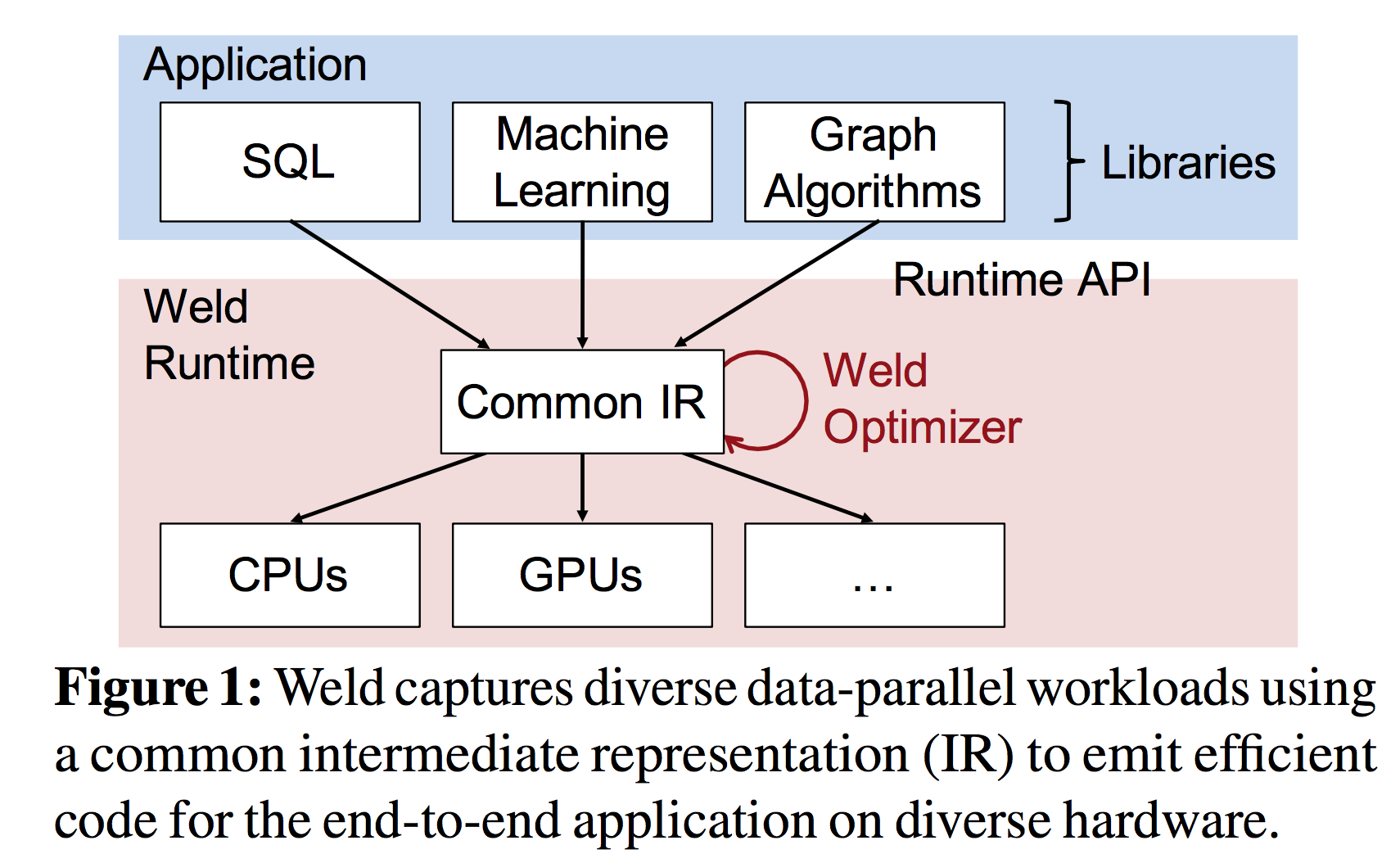
5.4 Runtime API 执行原理
6 Optimizer的实现
6.1 IR级别的优化
主要是通过Builder针对IR的代码进行优化, 比如对Loop进行优化, 比如对消除相同计算等等;
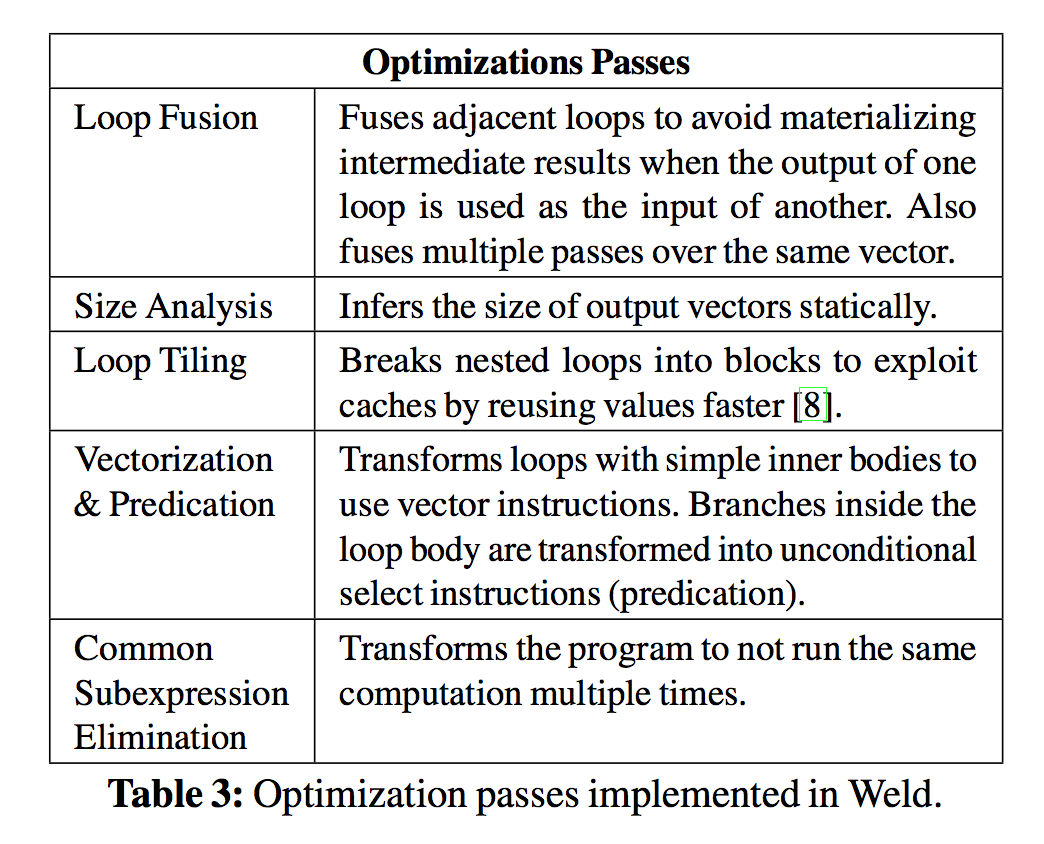
这里是Loop Tiling方法在Intel处理器上的优化效果
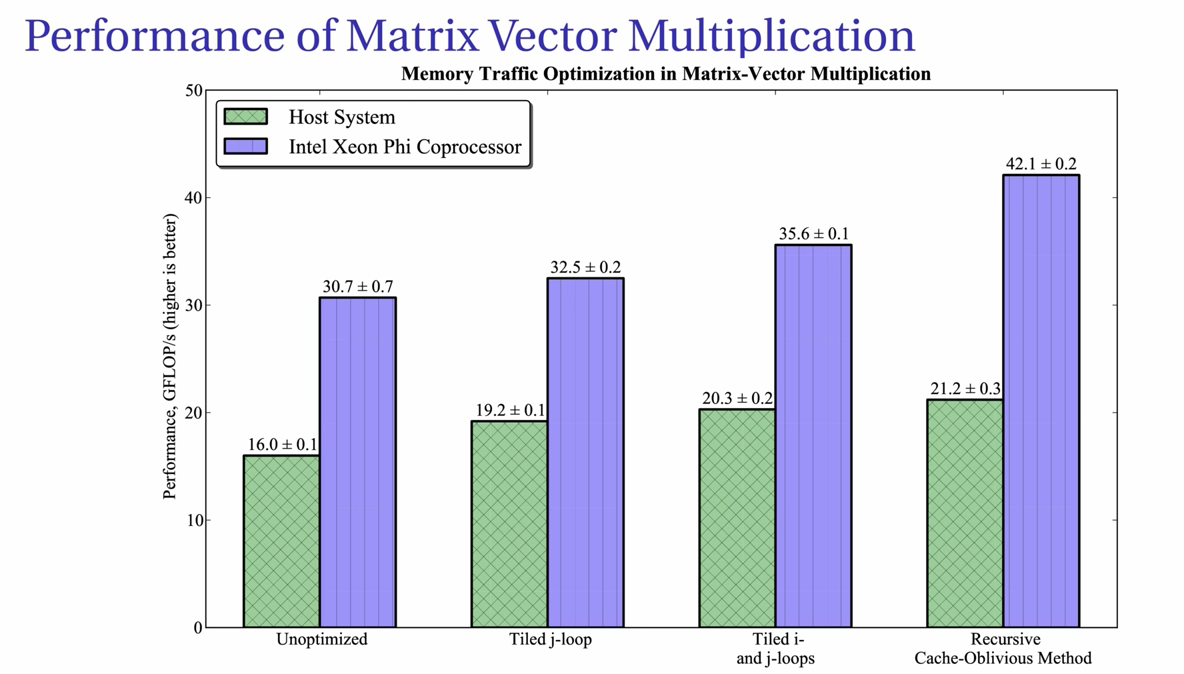
6.2 针对多核CPU的优化
Weld使用了LLVM来生成基于 AVX2指令集 的机器码, 运行时有一个特色, 就是代码运行在实现了work-stealing算法的执行引擎上, 这在多核上表现挺不错的;
6.1 针对GPU的优化
基于OpenCL做的GPU优化;
目前Weld只支持运行在单一种类处理器上, 还不支持co-precessor;
7 效果评估
大部分篇幅都在描述集成Weld过后, 这些工具提升了多少效果;
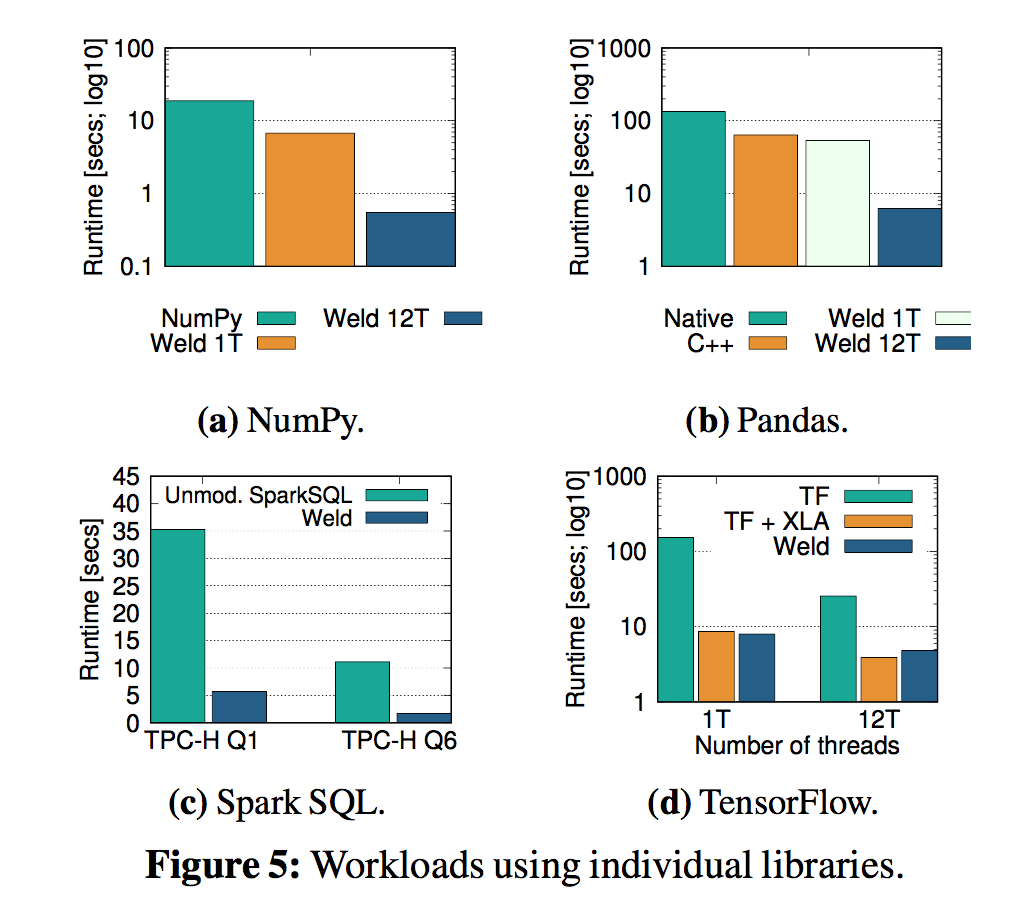
单独优化的效果(主要是多线程带来的):
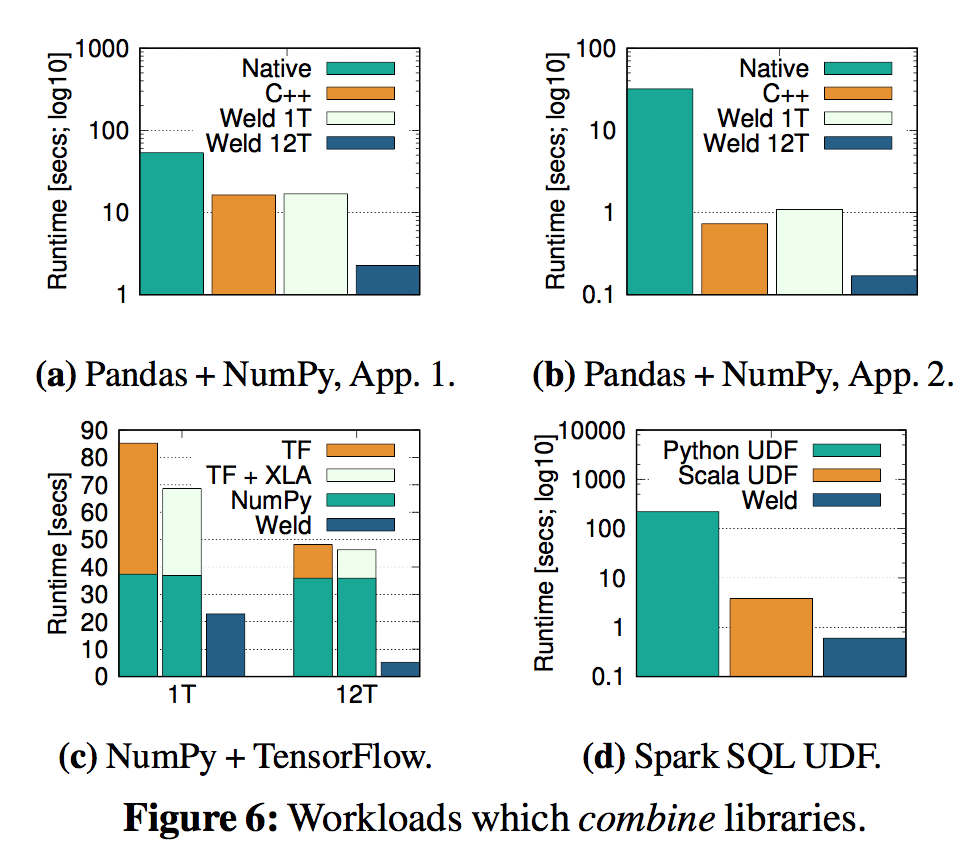
CLO的效果:
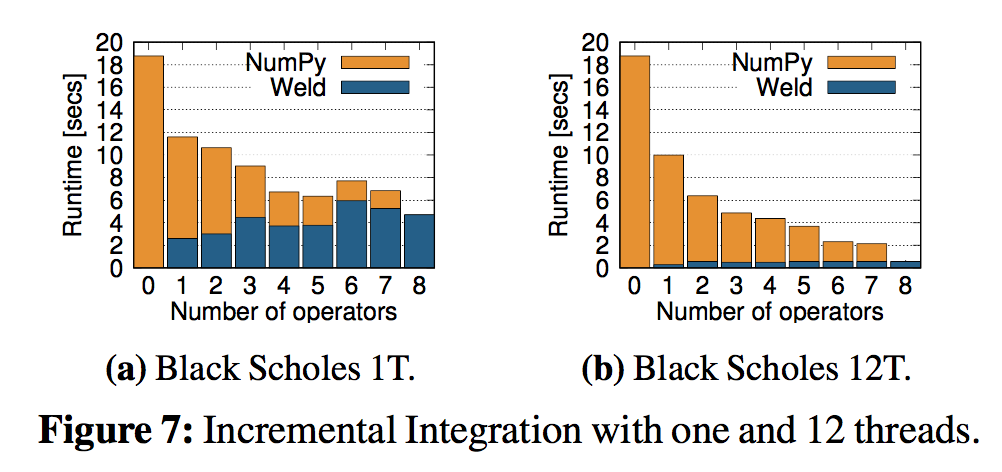
增量替换的效果(针对Numpy的):
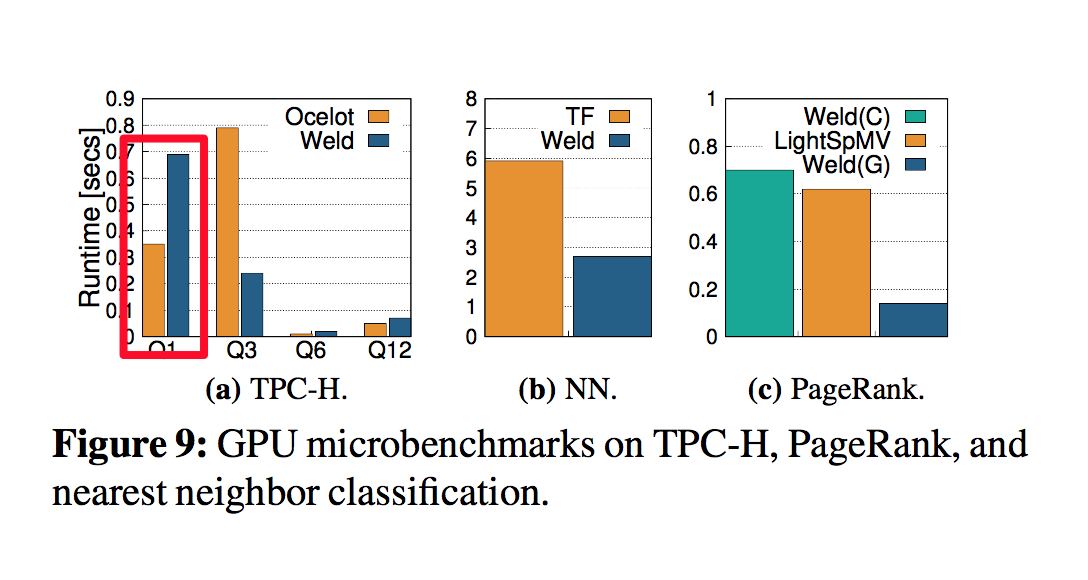
在GPU上的性能优化 (事实证明有些情况下, Weld也会比原生的库低效):