对数据压缩算法的调研
这篇是对多种数据压缩算法的原理, 实现, 效果的调研
数据压缩的原理
信息论
每段数据中所带的信息量是用熵表示的, 比如100KB的英文文本可能携带的信息量为1KB, 那么它最多只能压缩至1KB;
Reference: 香农信息论的熵
几种压缩算法的原理
字典算法
用特殊的几个字节代替频率很高的几个字, 组成一个dictionary, 即一个HashMap, 然后解压时从dict里面查询对应数据即可; 比如, 我们令 00 = China; 01 = San Diego; 10 = America, 那么就有下面的转换: I come from China, I will go to America San Diego. –> I come from 00, I will go to 10 01.
固定位长算法 Fixed Bit Length Packing
如00000001 , 00000100 这样的数字高位是浪费的, 所以可以将高四位省去, 保留低四位来节省空间
长度游程算法 RLE
RLE 即 Run Length Encoding, 有三个变种, 分别是:
- WWWWWBBBWWWW ==> 5W3B4W
- WWWWWBBBWWWW ==> XX5WXX3BXX4W (XX是特殊字符)
- A A A A A B C D E F F F ==> 85 A 4 B C D E 83 F
方法2比较常用, 但特殊字符最好在源数据中不存在, 或者出现的很少; 这是简单易行的有损压缩算法; WinRaR中使用了它; RLE的所有语言实现
哈夫曼编码 Huffman
一个Huffman在做学期报告的时候自己发明的, 示例如下:
-
源信息: FOFOEOEEEERRRRGGGGTTTTTTT
-
计算得到每个字段的频次表:
| 字段 | 频次 |
|---|---|
| F | 2 |
| O | 3 |
| E | 5 |
| R | 4 |
| G | 4 |
| T | 7 |
- 根据Huffman编码, 频次高的字段编码短, 频次低的编码长,
假设最短编码为两位, 那么递归将频次最低的两个字段相加, 那么我们可以得到这样的过程:
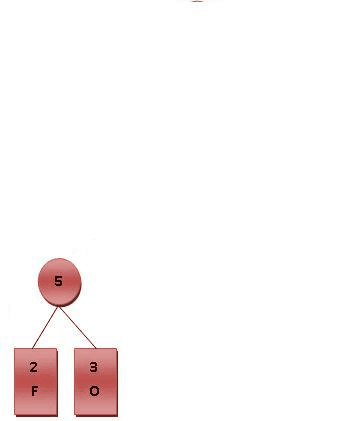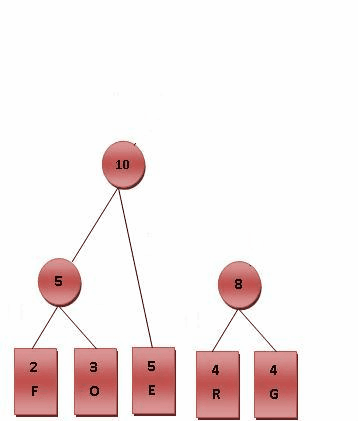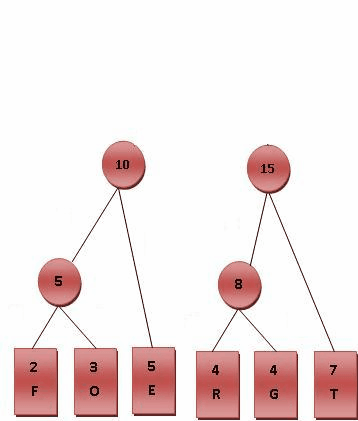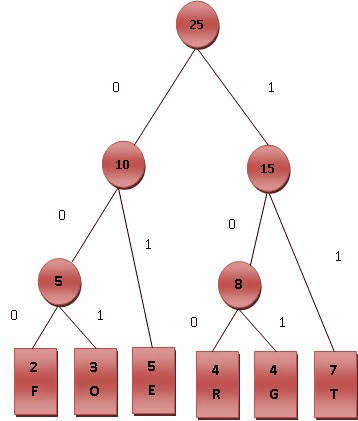
所以编码表为:
| 字段 | 频次 | 编码 |
|---|---|---|
| F | 2 | 000 |
| O | 3 | 001 |
| E | 5 | 01 |
| R | 4 | 100 |
| G | 4 | 101 |
| T | 7 | 11 |
-
Huffman是最好的无损编码, 就是速度略微有点慢,
DEFLATE 就是基于它的, gzip, zip都是DEFLATE的一种实现; -
在有噪音的情况下, Huffman比LRE好, 但Huffman的解码速度略慢,
而且要存储编码表, 数据量较小时, 编码表可能会占一个相对output的较大空间, 导致output反而比input大…
Rice 编码
- 是一种无损压缩算法
- 编码非常简单, 将值 X 用 X 个 1 位之后跟一个 0 位来表示.
- Rice编码的想法和Huffman类似, 只不过它是”静态的”,
不是根据文件每个word的统计信息来生成编码树, 而是基于小的值比高的值常见的假定决定,
这种编码在高值多的时候可以有一种优化, 将过大的编码output缩短;
LZ77编码 Lempel-Ziv
- 是一种无损压缩算法
- LZ77有特别多的变种, 什么LZ77 LZ78 LZO LZW啥的一大溜, 具体有多少无损压缩算法可以参考这个链接无损压缩算法归类和这个链接压缩算法归类
- LZ77有个好处, 就是能用O(1)的复杂度大致预估压缩后文件的最大大小;
- LZ77是个算法原理, 它的实现很多, 原理就是个滑动窗口, 这个窗口由 SB 和 LB 组成,
然后对于重复的字符串, 使用相对前面字符串的(offset + length)来代替;
这东西有个优化点, SB 可以用HashMap来代替;
压缩的实际应用
Hadoop在什么地方使用了压缩
-
透明压缩:
数据传到集群后,经过一段时间的冷却,我们会自动开启压缩任务,把数据压缩
节省成本 -
client写时压缩传输:
数据写入hdfs时,可以在client端经过压缩后,传到集群上,后端会解开
节省带宽 -
集群内部压缩传输: 集群内部在出现副本不足时,需要进行自动的块复制,补齐副本,这个时候会有压缩传输 已经压缩的块直接传,未压缩的块可以先压,再传,目的端不解压, 节省带宽
Hadoop的压缩算法比较
| 压缩格式 | 工具 | 使用算法 | 可分割性(splittable) | 压缩比率 | 压缩速度 | 解压速度 |
|---|---|---|---|---|---|---|
| DEFLATE | 没有这样的东西 | DEFLATE (Huffman + LZ77) | N | 高 | 慢 | 慢 |
| GZIP | gzip | DEFLATE (Huffman + LZ77) | N | 高 | 慢 | 慢 |
| ZIP | zip | DEFLATE (Huffman + LZ77) | Y (文件范围内) | 高 | 慢 | 慢 |
| BZIP2 | bzip2 | bzip2 | Y | 最高 | 超慢 | 超慢 |
| LZO | lzo | LZO | Y | 偏下 | 比snappy差点 | 比snappy差点 |
| Snappy | snappy | snappy | Y | 比lzo还差 | 最棒 | 最棒 |
- DEFLATE是基于Huffman和LZ77融合的压缩算法, 压缩效果好, 常用如GZIP;
- bzip2的压缩效果特别好, 但是特别吃CPU;
- lzo和snappy的压缩速度特别快, snappy这个哥么对x86的64位做了优化, 速度最快, 几乎不吃CPU, 但是压缩效果可能没有那么好;
文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率;
Google 的 Snappy 压缩算法
Snappy是一种使用LZ77的压缩算法, 它非常快的原因是它针对intel i7 core的三个优化:
- Snappy的大部分操作都是针对64位对齐数据的, 所以64位OS速度更快;
- Snappy假设不是64位对齐的数据仍旧开销较少;
- Snappy使用little-endian, 如果是big-endian的话, 他需要反转一下, 这样速度就慢了;
对于已经压缩过的数据, 如JPEG, Snappy也有优化:
Heuristic match skipping: If 32 bytes are scanned with no matches
found, start looking only at every other byte. If 32 more bytes are
scanned, look at every third byte, etc.. When a match is found,
immediately go back to looking at every byte. This is a small loss
(~5% performance, ~0.1% density) for compressible data due to more
bookkeeping, but for non-compressible data (such as JPEG) it’s a huge
win since the compressor quickly “realizes” the data is incompressible
and doesn’t bother looking for matches everywhere.
Snappy的github地址
关于little-endian和big-endian的wiki, 忘了的话可以看一下
非常重要的关于snappy的详细介绍
一个叫做Varint的数字Encoding方法, Google系的都用这个
L77的中文描述
L77的外国描述
上面的references全看完之后, 感觉成仙了….
References
知乎上的讨论 Hadoop的压缩算法选取 IBM的Hadoop压缩算法好文章 Clodera上的教你如何选择压缩算法 Markdown的语法系统学习